第一章:计算机系统概述
第一章:计算机系统概述
请记住,所有的程序都是指令序列+数据
比如一个C语言的HelloWorld的展示
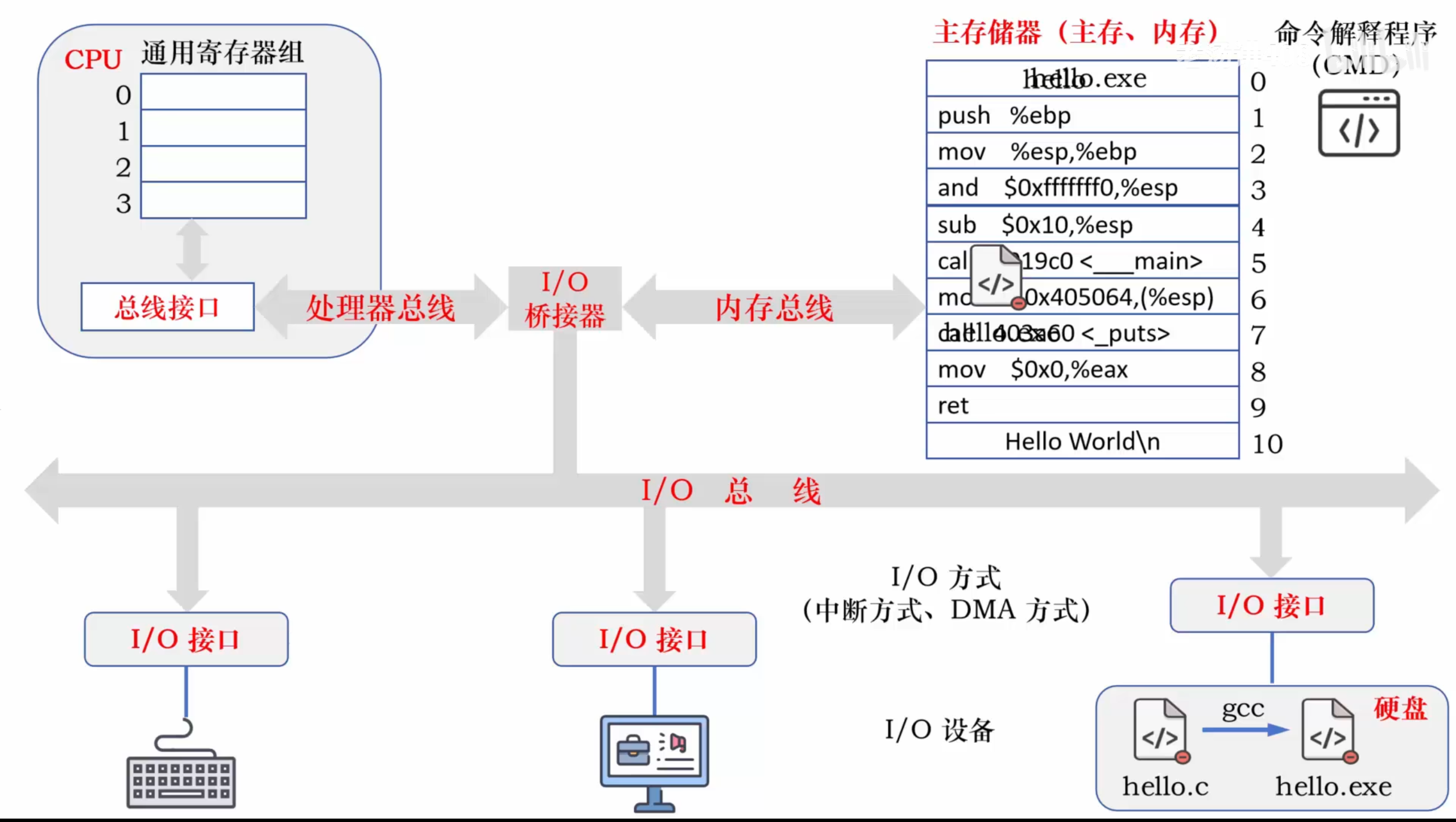
程序从硬盘复制到高速读写的主存储器中,然后从主存复制到CPU中执行,执行,最后数通过IO总线输出到显示器。
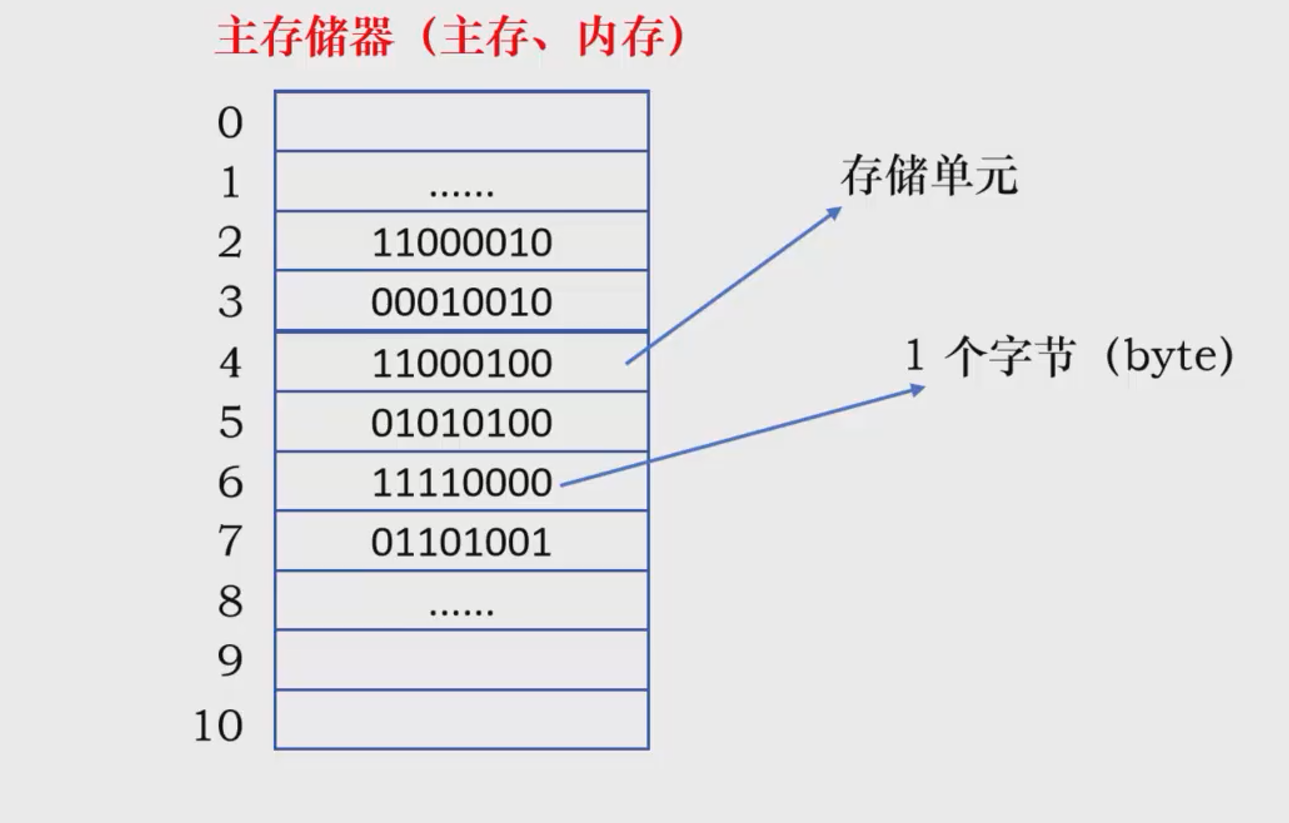
一般地,存储器被划分为若干存储单元,每个单元一般可以存放8个二进制位(就是8个数位,每个数位只能是0和1),而每八个二进制位就被称为一个字节(这个规律是计算机普遍适用的),所以主存可以理解为字节数组,其存储地址是连续的。
指令的设计
语言的发展历程:高级语言(C语言等)->汇编语言->机器语言(0-1代码)
机器语言就是0-1代码,前四个是操作码,是动词,后四个是地址码,是宾语,是被操作对象。
我在这里提到的是一个很简化的模型,没关系,第五章会详细讲到。


这样的指令集在不同的机器中是不一样的。
指令的执行
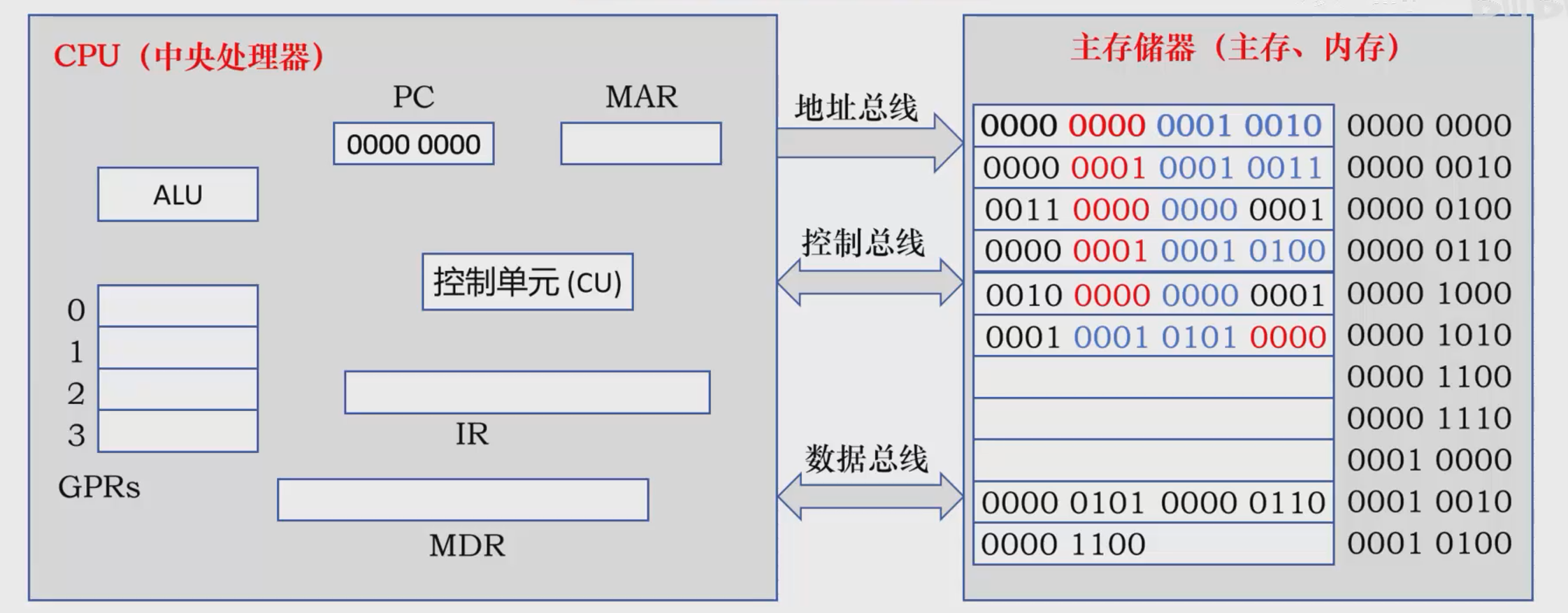
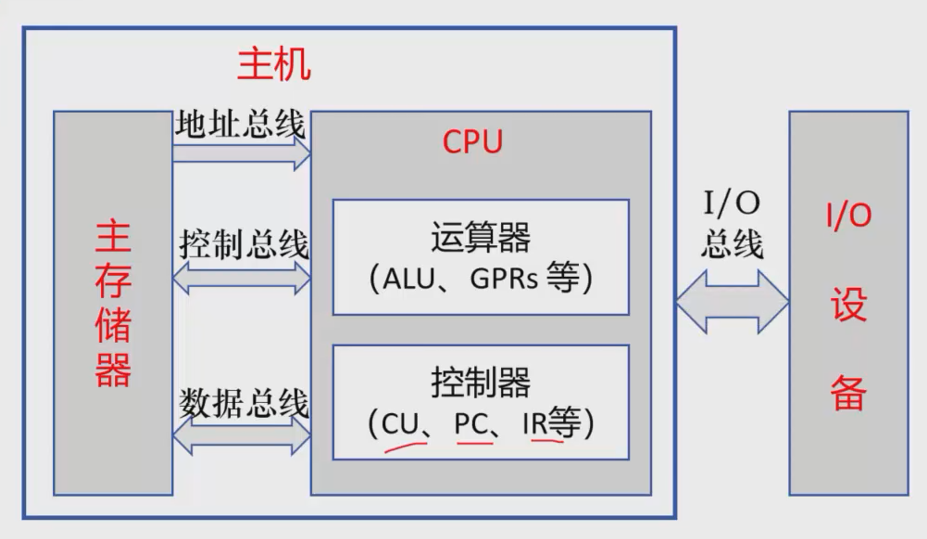
CPU与主存有三个总线,地址总线,控制总线和数据总线
还需要各种寄存器:
通用寄存器(GPRS)
程序计数器(PC):暂存下一条需要执行的指令,
指令寄存器(IR):暂存正在执行的指令
内存地址寄存器(MAR):临时存放内存地址
内存数据寄存器(MDR):临时存放数据
算术逻辑单元(ALU):对数据运算
控制单元(CU):发出控制信号和操作命令
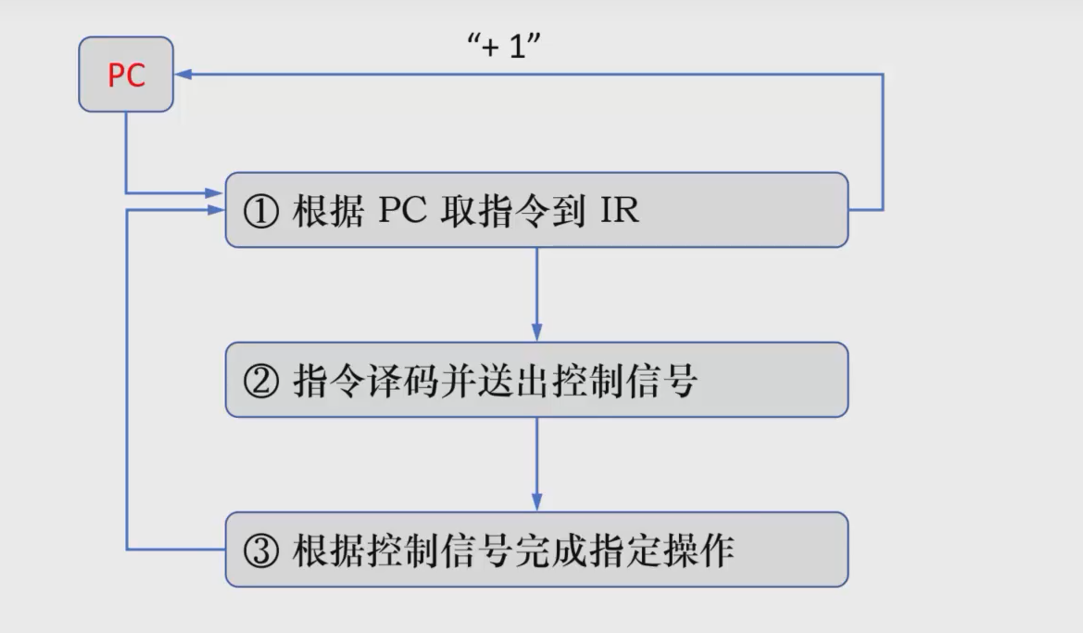
执行流程
主存中,左边的是命令,是主存这个数组中的数据,右边是地址,是数组的索引,建议配合上文图片阅读。
首先,主存的第一条内存地址会放到PC中,控制单元会向PC和MAR发送控制信号,将PC中的地址传到MAR,MAR通过地址总线传到主存,CU通过控制总线将控制信号发到主存,主存将地址对应的数据通过数据总线走到MDR,(此时MDR中的是待执行命令),CU给MDR和IR发送小信号,将MDR的数据存放到IR中,这就完成了取出指令(取指)的操作。
随即PC自增2(也不一定是2,取决于实际指令长度),切换到主存中的下一个索引,执行下一条指令。
CU会分析IR中的操作码,给IR和MAR控制信号,将源操作数(目标)的地址通过地址总线传输到主存,CU再发送控制信号,主存会将根据接收到的地址将目标的数据通过数据总线发回到MDR,随即CU向通用寄存器和MDR发送信号,MDR的数据转移到0号寄存器。
在引入两套数据之后,下一条引入的指令往往是操作而非数据,CU会根据需要给ALU发送指令,将寄存器中的值进行加减乘除操作,并将结果存入到目标寄存器地址中。
总结
+1指的是移动到下一指令的操作,具体加多少需要看指令长度
冯诺依曼计算机结构
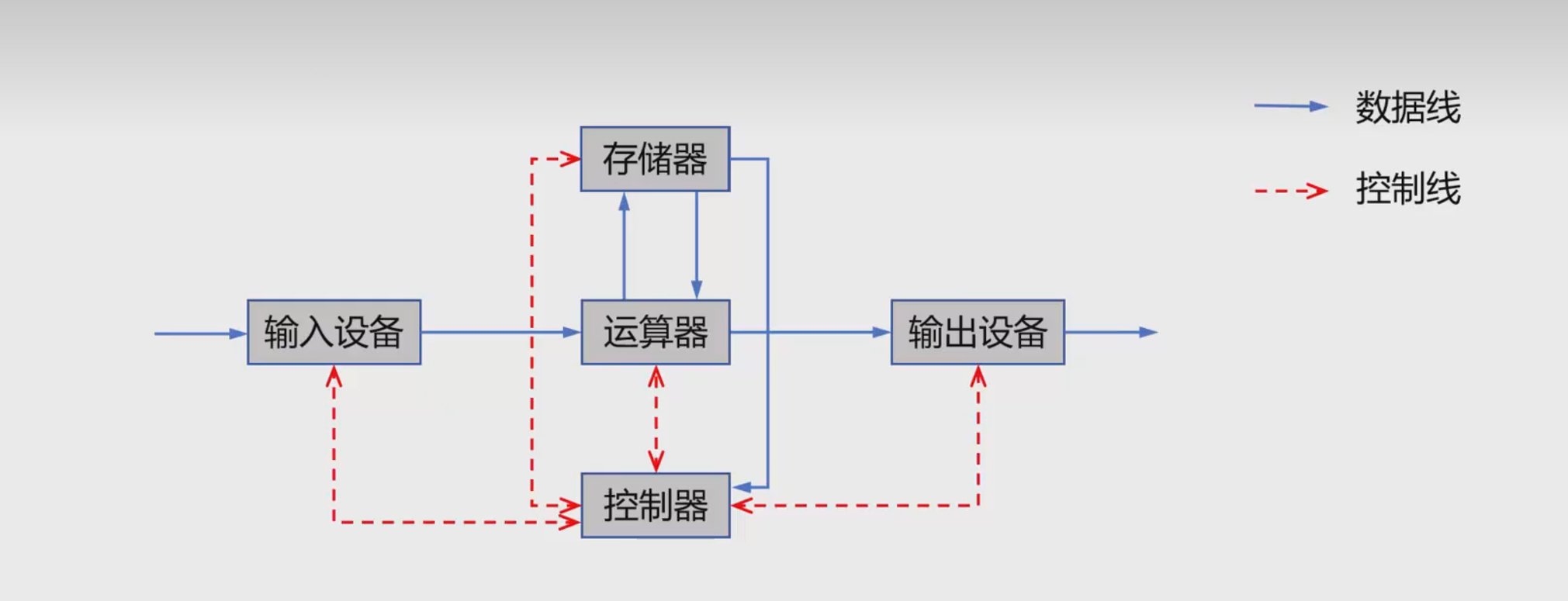
注意:存储器包括 输入设备 输出设备 控制器 运算器
运算器:执行算数运算和逻辑运算
存储器:存放内存和指令,分为主存(内存条)和外存(硬盘)
控制器:指挥中心,发送指令与控制信息,包括前文提到的PC,IR,CU
在那个年代,这种计算机结构以运算器为中心,参与存储和输出的工作,这就使得容易达到性能瓶颈。鉴于冯诺依曼具有跨时代意义的设计,现代计算机很大程度上沿用了冯诺依曼结构,但是以存储器为中心,只有需要计算才会使用运算器,这样就能将存储和输出与运算器解耦,解放性能。
实际上,运算器和控制器联系紧密,往往集成在同一个芯片(IC)上,这块IC名为中央处理器CPU。
总结
冯诺依曼计算机结构有五个特点:
①:计算机由运算器、控制器、存储器、输入设备和输出设备5个基本部件组成
②:指令和数据以同等地位存储在存储器中,形式上没有区别,但计算机应能区分它们
③:指令和数据均用二进制代码表示
④:指令由操作码和操作数组成两部分组成,操作数可以是多个
⑤:采用“存储程序”工作方式
存储程序:将事先编制好的程序和原始数据送入主存储器后才能执行,一旦开始执行,不需要人员干预就会自动逐条执行完毕。
语言的编译过程
高级语言翻译成机器语言程序一般是使用编译器和解释器,编译器会一次性将所有的代码编译成机器码,解释器逐行解释为机器码
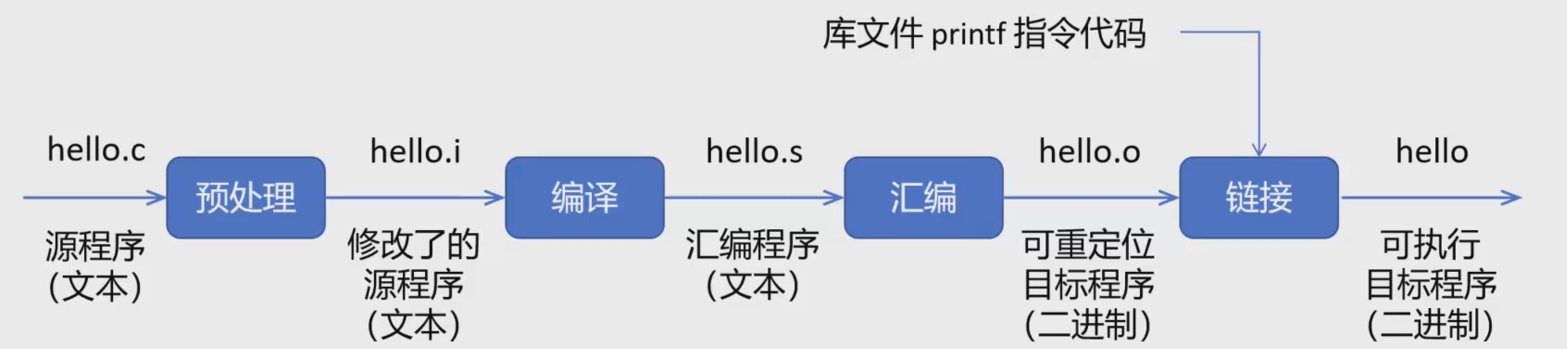
第一阶段是对C文件略作修改,对#include的预处理指令做解析和替换。
第二阶段是将C语言翻译成汇编程序,仍是文本
第三阶段是将汇编程序转化为二进制机器码,这一阶段已经不是文本了,所以直接打开会乱码。
第四阶段是将程序中的函数连接起来,形成一个整体的exe,供执行。
你可以使用编译器来实现“半编译”的效果。
解释器会将一行的指令解释为机器语音指令,直接可执行。
抽象能力很重要,梳理需求的时间比操作时间长的多。
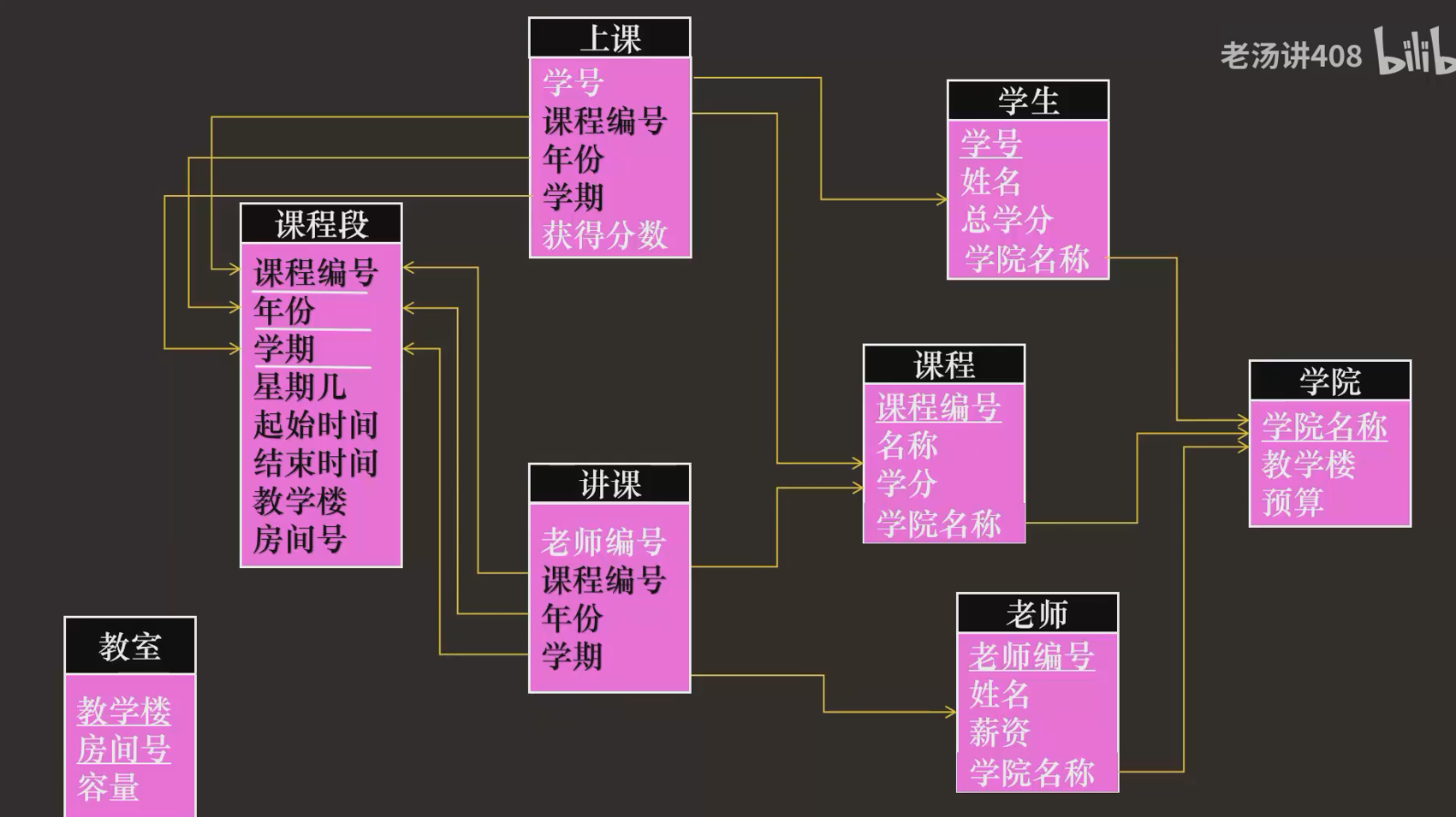
很多时候可以用“教室”“课程段”来集合我们的多对多关系。
计算机系统的层次结构

每一层都是由下一层支持的,每一层又在支持着上一层
底层是晶体管,一般是MOS管,mos管内部有一个电压阈值,能够依据电压调整导通情况,高于阈值的电压称作高压,反之低压。
NMOS:高压导通,低压不通
PMOS:高压不导通,低压导通
逻辑电路:低压表示0,高压表示1,使用晶体管可以方便地运行与或非运算。
一般地,我们只需要知道数电课里的表示就可以了,原件内部的半导体如何摆放,如何设计的,那不是很重要。
操作系统负责掌控计算机的每一个硬件,控制程序调度
其实在操作系统层和功能部件层中包括了两层,是指令集体系结构(ISA)和微体系结构。
ISA:定义了计算机可以执行的所有指令,规定了指令对应的操作,规定了操作数存放位置和操作数类型
微体系结构:比如指令的流水线设计,加法器的进位方式,等等,规定了ISA的具体实现
计算机的软件和硬件在逻辑功能上是等价的。
我们会加速经常性行为来增强性能。
计算机性能评估指标
三个性能指标:
- 时钟周期(Clock cycle)
- 时钟频率(主频)
- CPI
时钟周期:就是CPU执行操作的节奏,CPU一般是一个周期执行若干固定数量的操作。
如果一个指令是5个时钟周期,一个时钟周期试试20ms,那么执行指令需要100m
所以,周期越短,执行速度越快。
主频:就是时钟周期的倒数,主频越大,执行越快。
CPI:执行一条指令需要的时钟周期数
当然这是分情况讨论的,如果是一个指令那就是执行这条指令的花费周期
如果是一个程序,那就指的是该程序所有指令执行所需的平均时钟周期数
如果是一台机器,那就是执行该机器指令中所有指令执行所需的平均时钟周期数
CPU执行时间 = 程序指令条数 * CPI * 时钟周期
我们能够通过修改指令集来减少程序总指令条数,但是那样会导致CPU结构变化,可能增大时钟周期。三者相互制约,增强性能的方式往往都是有代价的。
三种性能指标的评估方式
方法一:用指令执行速度评估
IPS:平均每秒执行指令数量
IPS = 主频/平均CPI
IPS越高,性能越好(待证实,很多时候现实不是这样的)
MIPS(Million IPS):平均每秒执行多少百万条指令
MIPS = IPS * 10^-6
例题:
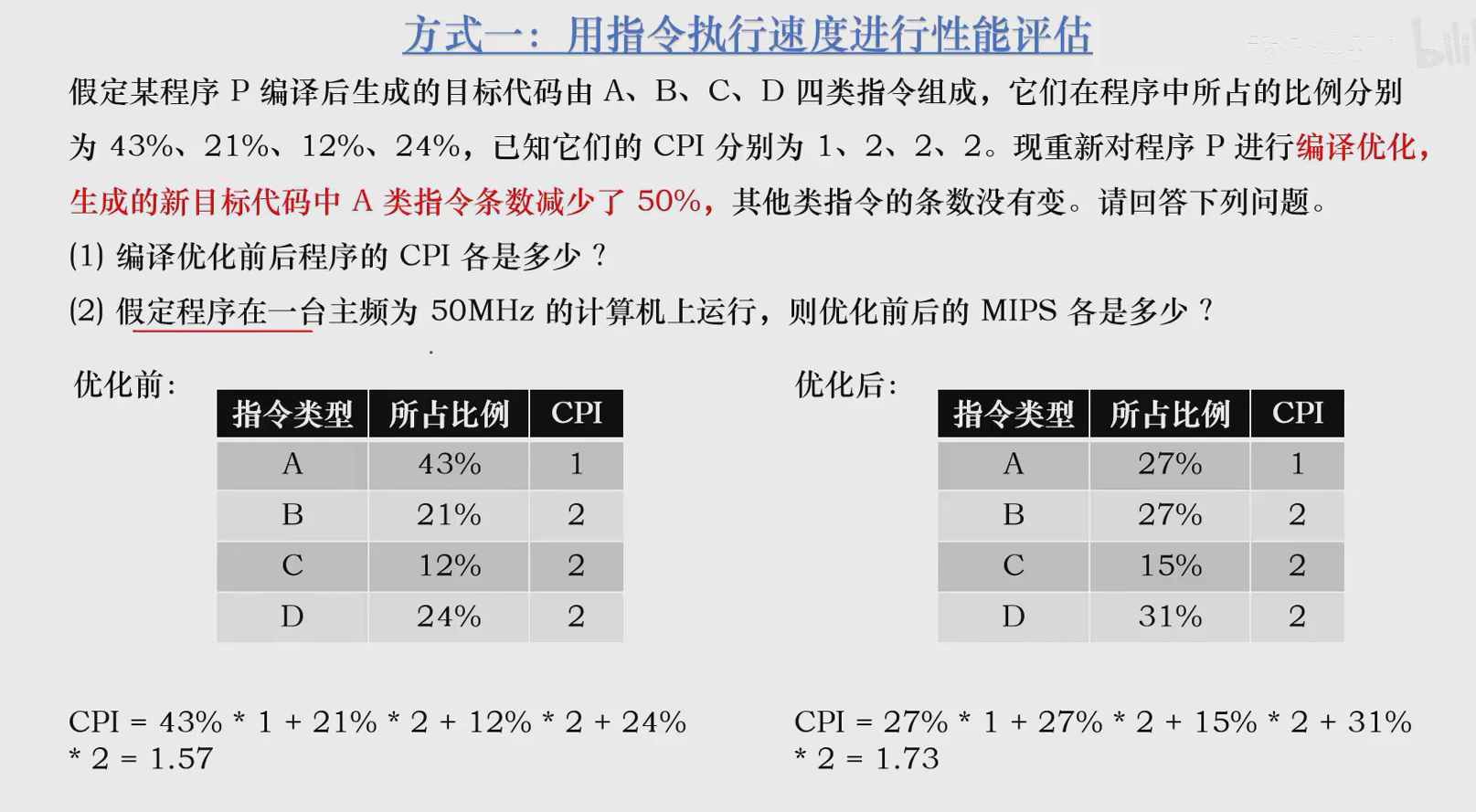
FLOPS:平均每秒执行多少次浮点运算操作
类似于MIPS,有MFLOPS,GFLOPS等类似的指标,只有单位上的不同
方法二:用基准程序进行评估
同一个基准程序,在两台计算机执行的时间差就能够拿到性能差,但仅仅使用一个程序是不全面且不科学的,所以玩往往会用到一组程序。
基准程序是专门用来进行性能评价的一组程序
如SPEC测试程序集,分为了整数测试程序集SPECint,浮点型SPECfp,CPU性能测试集SPEC CPU 2000,WEB测试 SPEC web等。
方法三:阿姆达尔定律
基本思想:对系统中某个硬件部分,或者软件中的某部分进行更新所带来的系统性能的改进程度,取决于该硬件部分或软件部分被使用的频率或其执行时间占总执行时间的比例。
通俗的说,就是针对某一处硬件或者软件修改,看修改后性能增强了多少。这取决于计算机执行这个操作的频率高不高,高的话能吃到的增强就越多。

例如:
