第六章:中央处理器
第六章:中央处理器
全章节学习路线:
数电基础
组合逻辑电路在任何时刻的输出信号的稳定值,仅仅与该时刻的输入信号有关,而与该时刻以前的输入信号无关。
但时序电路的输出不仅取决于当前的输入,还取决于电路原来的状态。
CPU是边沿反应的,这是为了阻止输出信号震荡的问题。
中央从处理器
CPU由数据通路和控制单元组成。
CPU内部集成了一根内部总线,但是存在信号碰撞的问题,也就是在同一时刻只能传输一个数据。
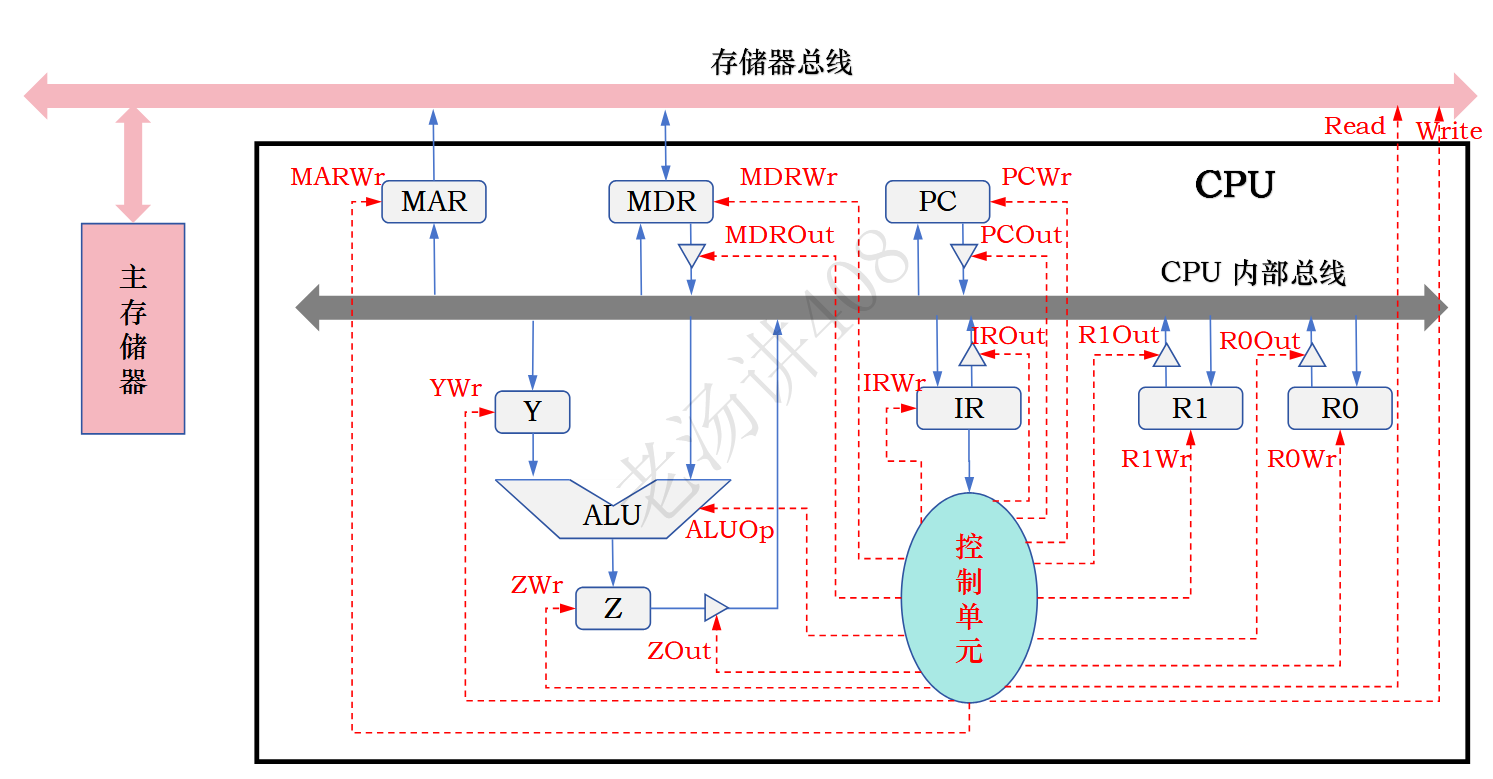
元件是否进入总线是由三态门把关的,三态门接收到使能信号就允许通过,反之成立,每个三态门都与控制单元连接。控制单元还通过使能信号端来控制每个元件。
数据通路指的是:指令执行过程中数据经过的路径,包括路径上的部件,称为数据通路。
控制单元根据每条指令的功能不同生成对数据通路的控制信号,并正确控制指令的执行流程。
取指阶段
需要执行的指令存在主存中,那么将指令cong主存读取到CPU的过程就是取指阶段。
取指阶段由六个微操作组成。
第一步,CU向pc和mar发送信号,PC的主存地址会通过总线传输到MAR中,MAR将通过总线送到主存中
第二步:CU向主存发送信号
第三步:主存返回指令存放到MDR
第四步:向IR和MDR发送信号,将 MDR发送到IR
第五步:将IR发送到CU进行译码分析
第六步:译码分析并执行完毕后,CU向pC发送信号使PC自增1
为了加速单次取指的时间,我们需要注意:部分微操作的次序不可改变。
被控制对象不同的微操作应尽可能放在同一个时钟周期节省时间。
占用时间不长的微操作应该安排到同一个时钟周期内完成,允许其有不同的次序
注意看,第一步和第二步的被操作对象不同,那么我们就能够将他们放在同一个时钟周期内
第三第四第五步有先后顺序,不能改变。
但是第六步自增可以和第三步安排在同一时钟周期。
只要这两个微操作不冲突(不使用同一总线或功能部件),就能够放到同一周期以优化性能。
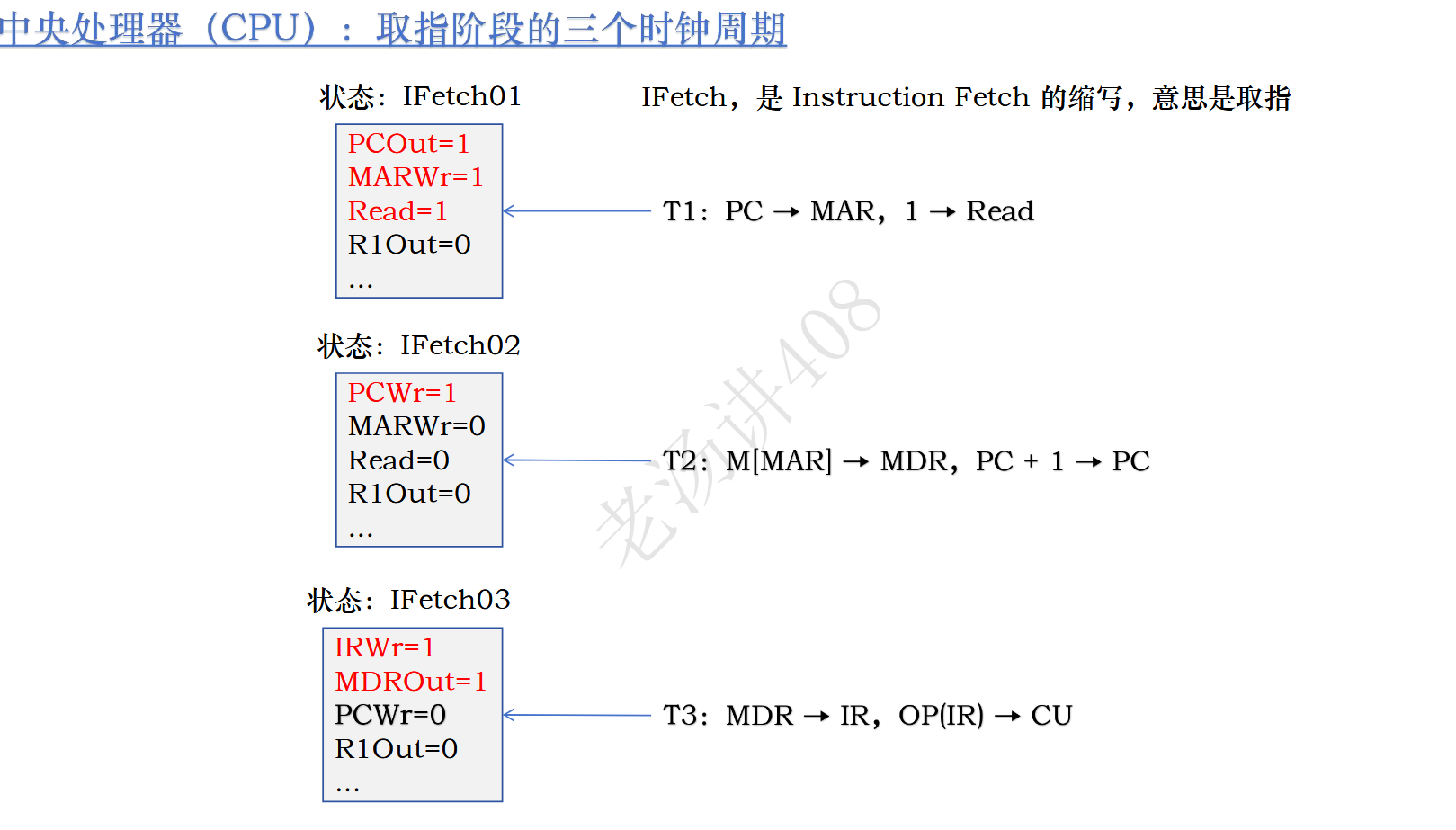
所以,加速后的操作次序就是
T1:PC -> MAR,CU->Read
T2:M[MAR]->MDR,PC++
T3:MDR->IR,OP[IR]->CU
执行一次取指需要三个时钟周期,
执行阶段
假设这是一个CPU的指令集:
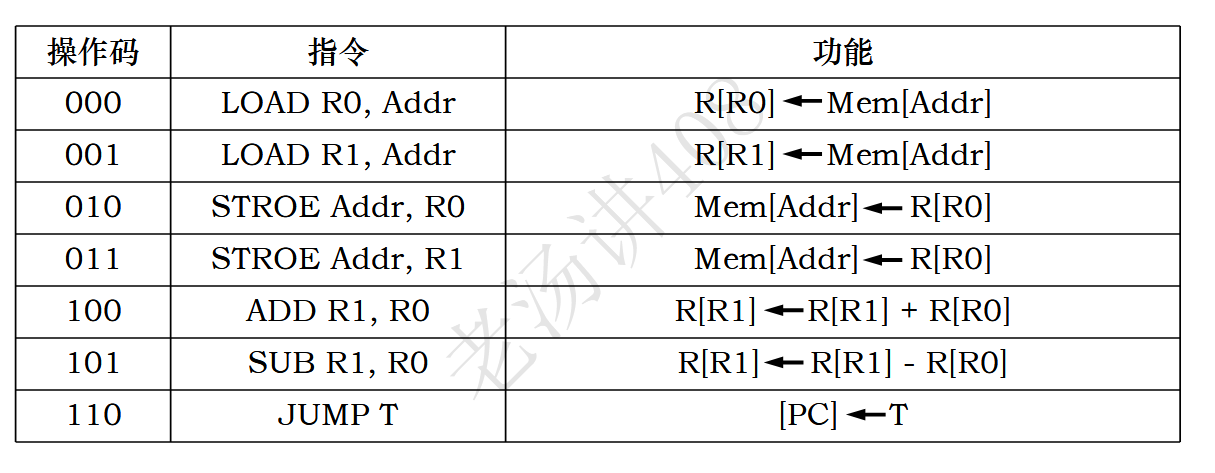
第一条是将制定主存地址的数据加载到寄存器R0中。
执行起来有三步。
T1:Ad[IR]->MAR,1->Read 将IR中的地址经过MAR发送到主存,CU发送控制读信号。
T2:M[MAR]->MDR 将主存中对应地址的数据取出到MDR
T3:MDR->R0 将MDR的数据存入到寄存器R0中。
再比如,倒数第三条指令,是将R1和R0做加法存到R1
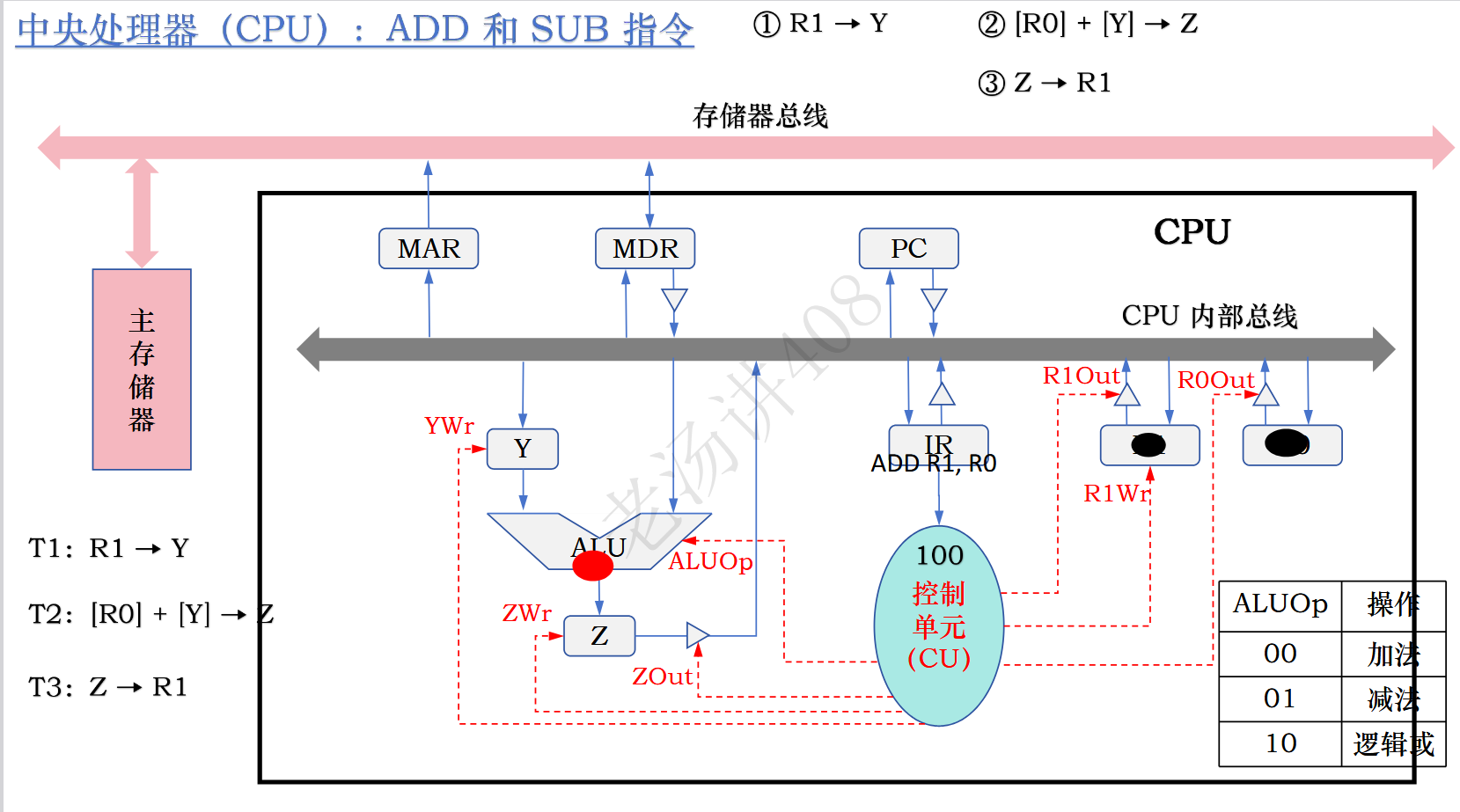
T1:R1->Y将R1的 值赋给Y
T2:[R0]+[Y]->Z 这一步需要CU发送00指令
T3:Z->R1
这三部用的都是同一个对象,不可再做任何优化
再看JUMP无条件跳转指令
这个很简单了,就是
T1:Ad[IR]->PC
指令周期:取出并执行一条指令所需的全部时间
指令周期可以看作是取指周期(Fetch)和执行周期(STORE)组成
取指周期完成取指令和分析指令的操作
执行周期是完成执行指令的操作
控制单元是如何实现的
控制单元的职能是译码分析,执行指令,发送控制信号等
组合逻辑控制单元
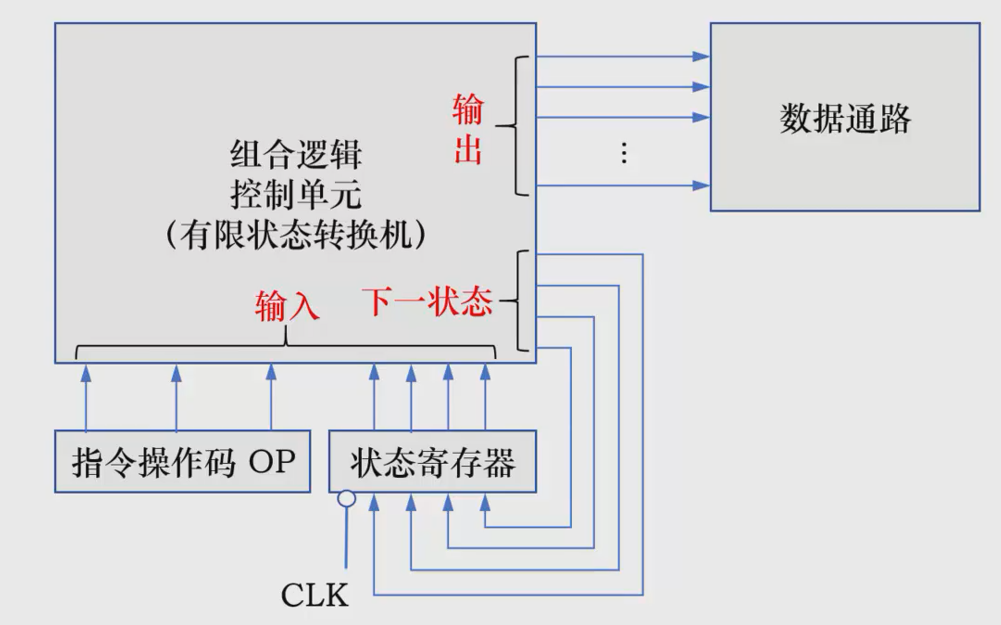
使用门电路实现,又名硬部件控制单元,适用于早期计算机。
其执行速度非常快,原子速度接近光速,但是结果复杂,实现困难,不容易扩充和修改指令,可塑性非常差只适合RISC指令系统,但在追求极致速度的场景下也会使用。
微程序控制单元
微程序控制采用”存储器替代逻辑”的思想,将机器指令的执行转化为微程序的执行。
微程序是一个微指令,一条伪指令包括若干微命令,一条机器指令功能由一个微程序完成。
你记不记得我们说过,CU能够给每个元件发送控制信号?
那么请回忆计网那本书的内容。CU能够将对所有的元件发送的信号组合成一个长二进制(也就是一条微指令),每一位都对应不同的元件,随后将该二进制在一个时钟周期内广播,就完成了发送控制信号的工作。
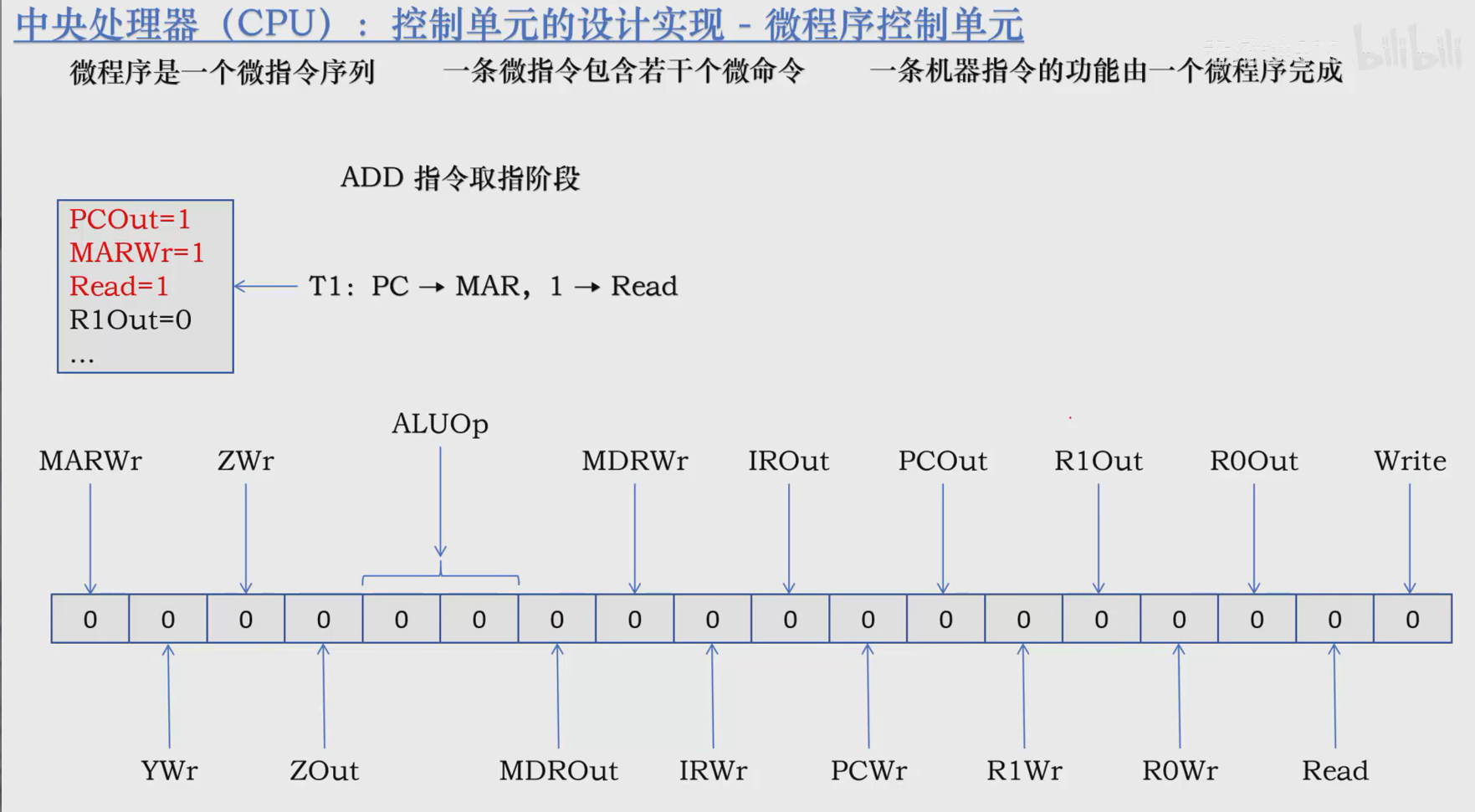
那么取指阶段的三个微操作就对应了CU发送的三条微指令,执行ADD命令也是如此。
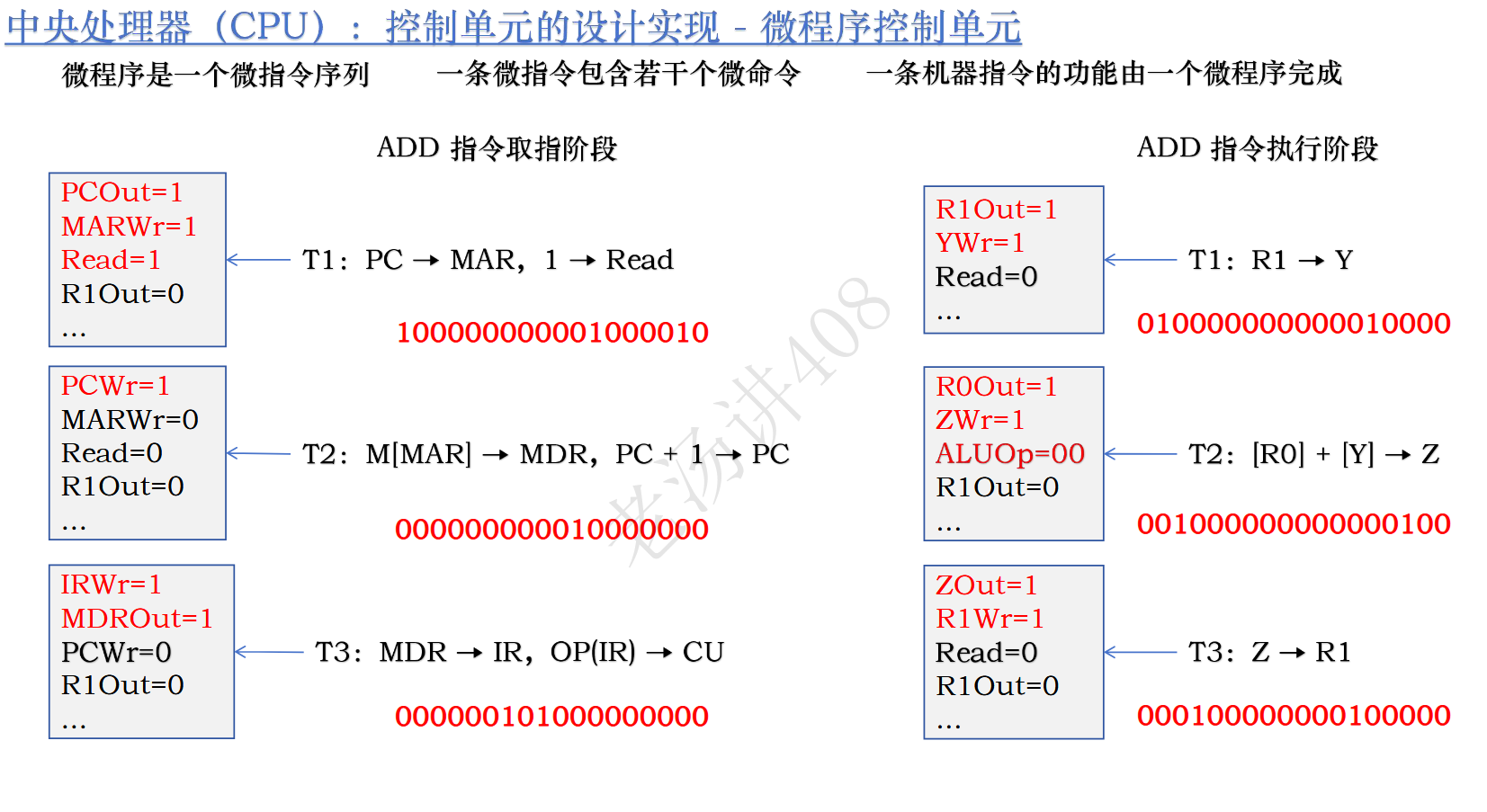
这六个微指令合在一起就是微程序,一个微程序就完成一条机器指令的功能,因为取指是公共操作,所以我们会将取指的三个微指令作为一个独立的微程序。

这些微程序存放在CU的控制存储器(Control Storage)当中,是一块只读ROM芯片,简称CS。每一条微指令都有对应的微地址。
还有一个起始和转移地址发生器,能够生成下一条微指令的微地址,并存入uPC中(与CPU中的PC功能类似)。指令寄存器uIR会根据uPC的地址获取对应的微指令,控制单元开始译码uIR中的指令并对相应的元件发出相应的控制信号到数据通路中,最后在时钟信号的控制下uPC自动加1.
微程序控制单元中的转移控制模块能够洁厕出下一条指令的微地址
下一条指令地址的决策
执行完一条指令后,下一条指令地址有三种方法得到:机器指令操作码,uPC++,控制转移字段。
CS中,每个指令末尾都带两位二进制作为控制转移字段。控制转移字段能决定下一条指令的地址选取,就是图中的MUX多路选择器的输入。
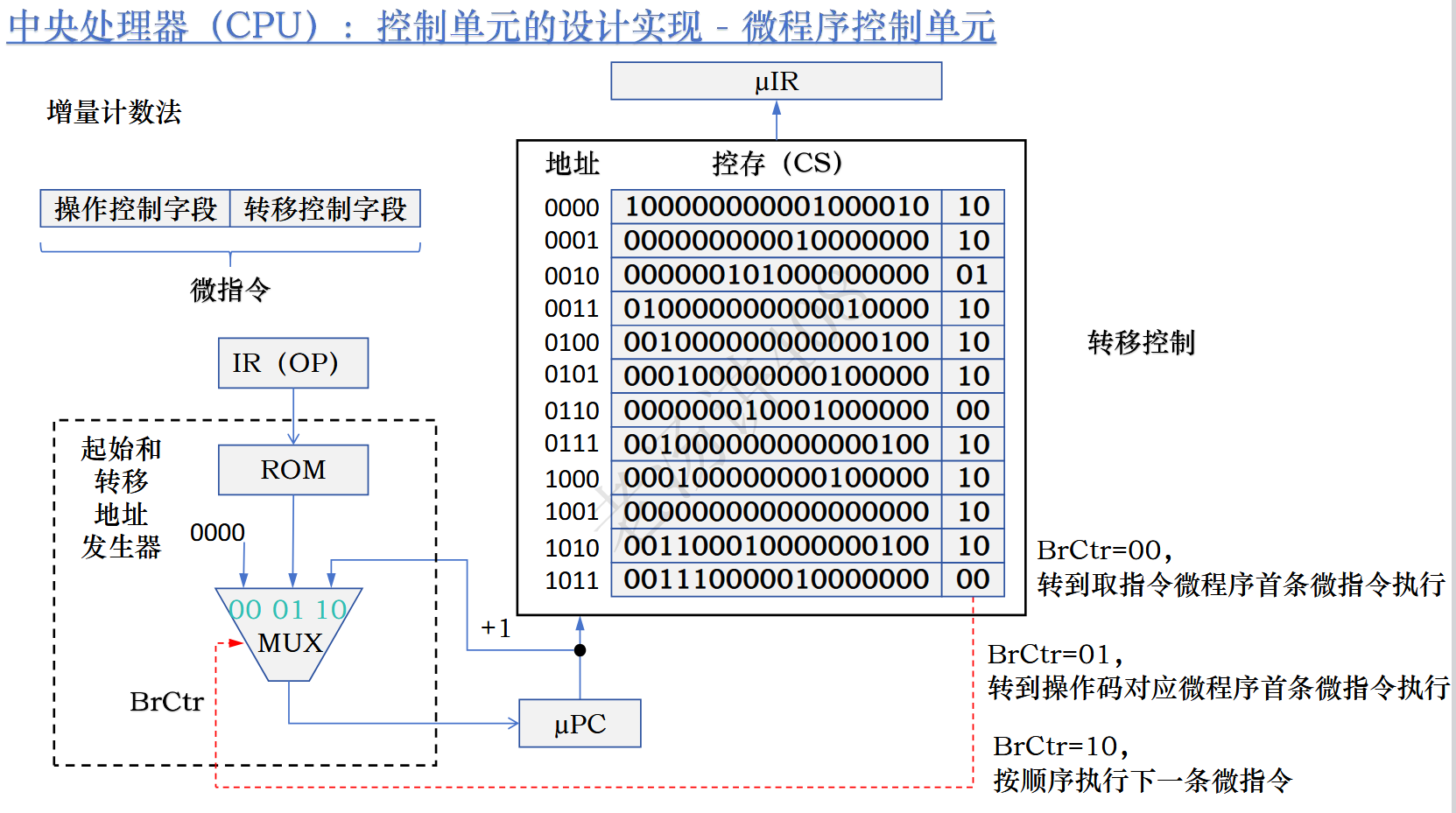
这种三合一的计数方法,因为大多数是时候都是程序顺序执行,所以在大部分时间都是uPComing增量+1操作,所以我们称其为“增量计数法”,这样的计数法要求微指令必须是顺序存放的。
针对不是顺序存放的我们使用“断定法“。
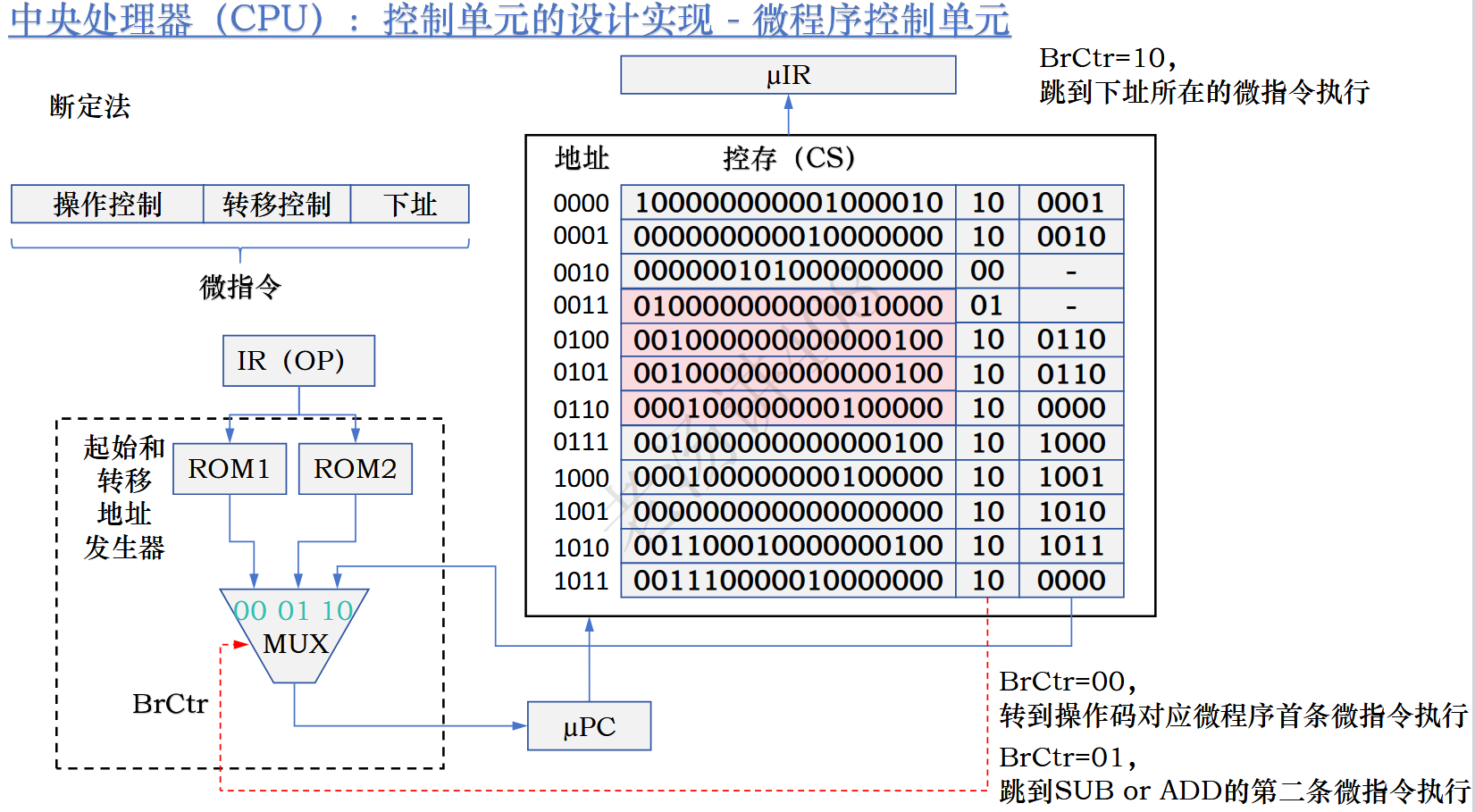
下址就是下一条指令的微地址。
这样虽然空间利用率低,但是确实能够解决非顺序存放的问题。
微命令编码问题
比如这个过程:
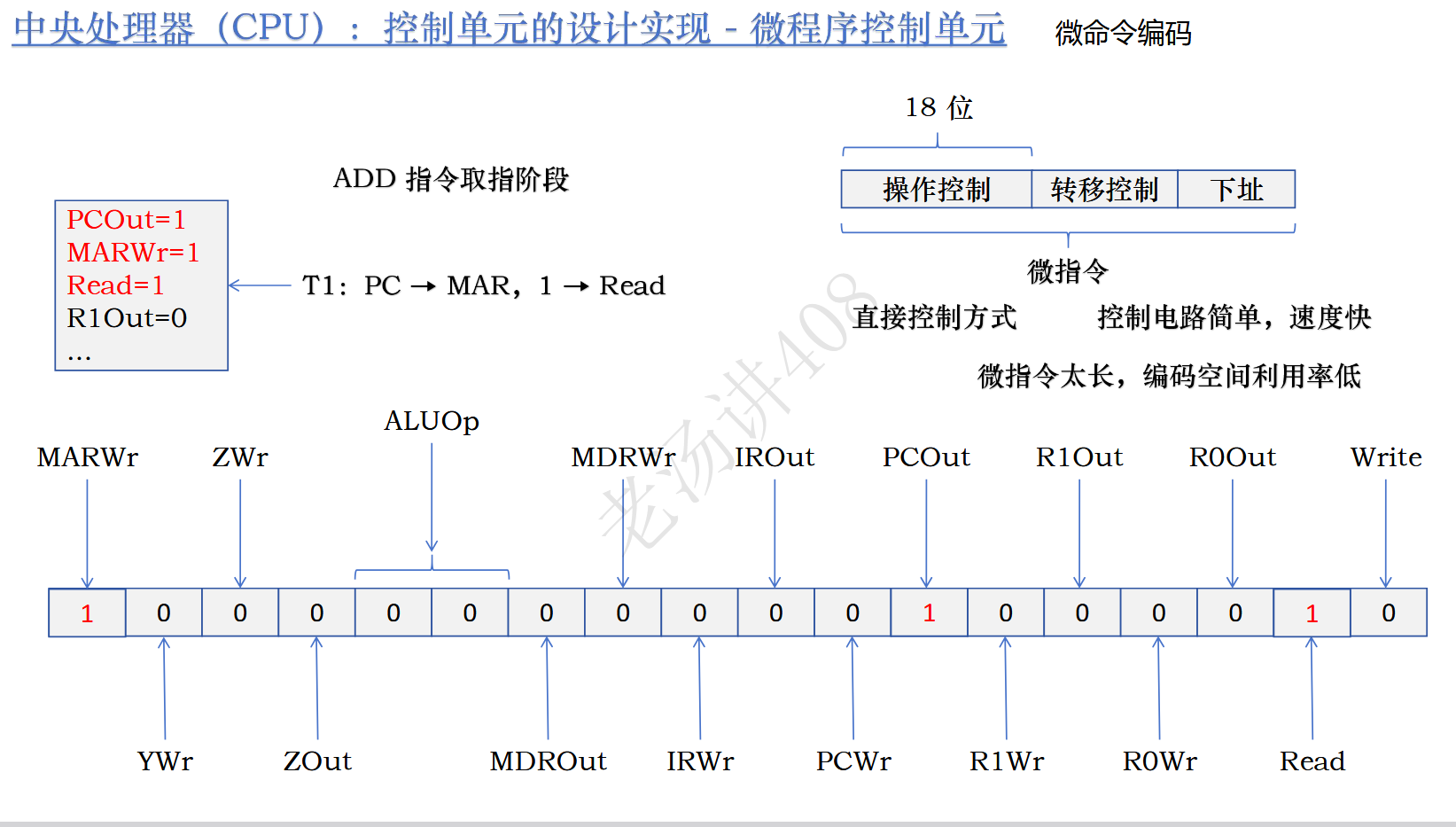
这么长一个微指令只有三个1信号,这就显得空间利用率低。另外,因为1->Read,PC->MAR,MDR->IR都需要占用总线,这意味着他们是互斥微命令,不能同时执行。这意味着所有相同后缀的互斥信号都因为互斥能够统一管理和编码。
所以,我们可以将相容的输出信号放到一起,统一编码来优化空间利用率。
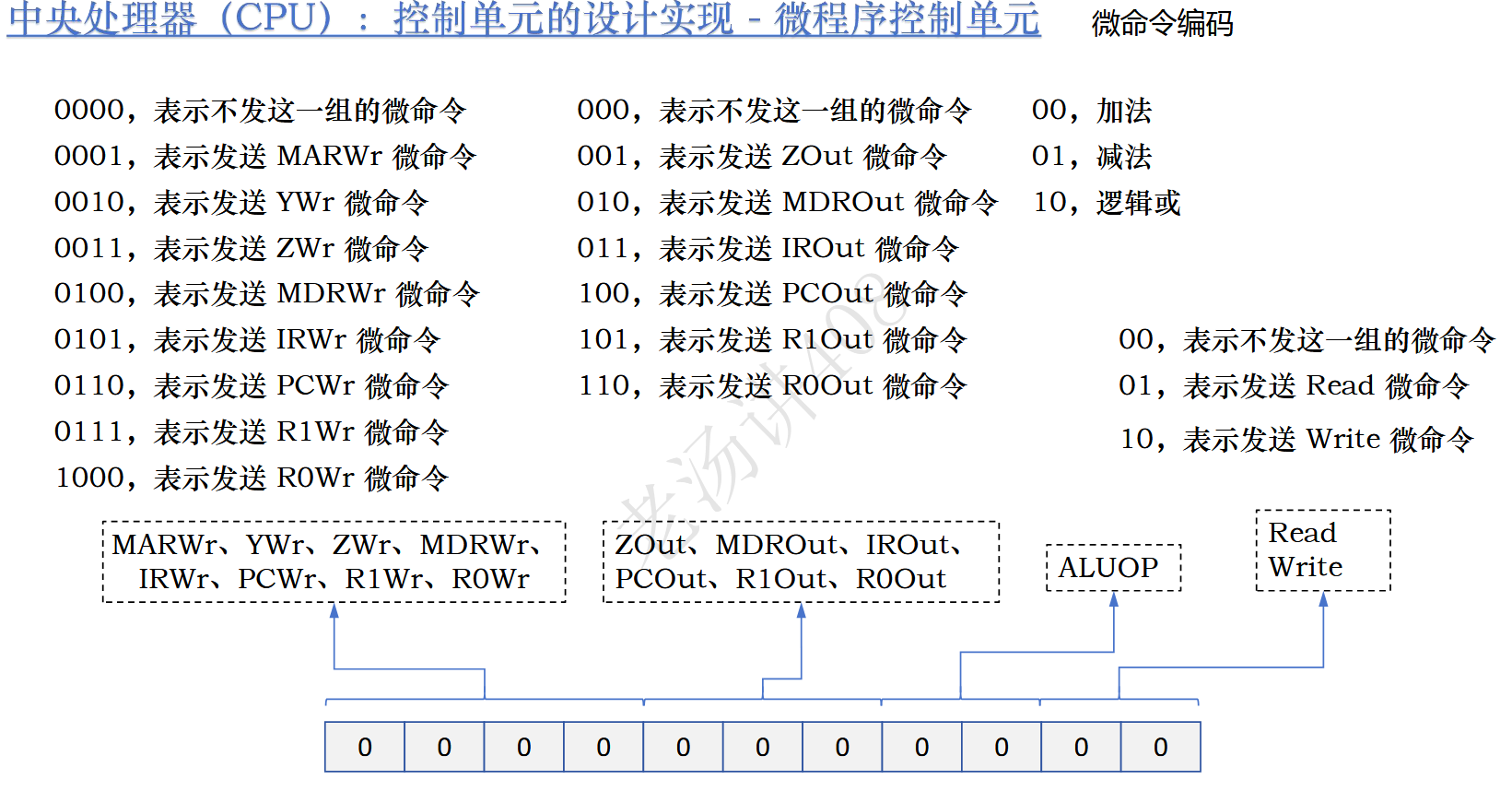 这样空间利用率就得到极大优化,这样的编码法叫做字段编码法
这样空间利用率就得到极大优化,这样的编码法叫做字段编码法